Contents
Nucleotides and Nucleic Acids
ATP
ATP contains three phosphate ions that play a significant role in energy transfer. It is essential to metabolism, which is all the chemical reactions that take place in a cell.
ATP, or Adenosine Triphosphate, is an immediate source of energy for biological processes. For metabolic reactions in cells to continually occur, there must be a constant, steady supply of ATP.
The emphasis is on IMMEDIATE energy source. This is what is unique about ATP compared to other molecules that release energy, such as glucose, and therefore must be stated in exams to get the mark.
Below is a diagram of ATP, and this is the level of detail that you need to remember the structure in. ATP is composed of adenine, a nitrogenous base (meaning a base that contains nitrogen), ribose (a pentose sugar), and three inorganic phosphate groups. The phosphate groups are described as being inorganic because they do not contain any carbon atoms. For this reason, in chemical reactions, the symbol to represent this is a P for phosphate and i for inorganic - Pi
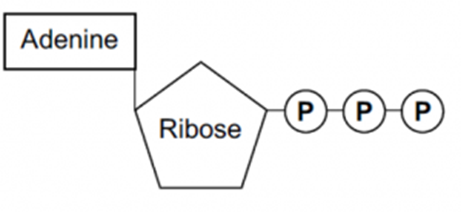
A more detailed diagram of ATP is below.
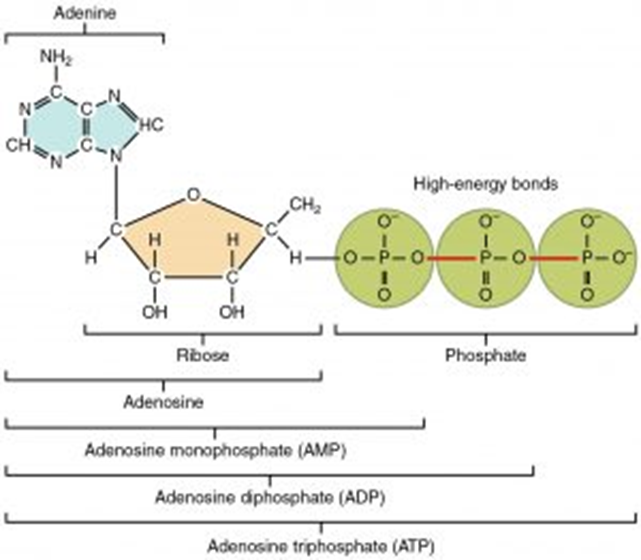
ATP is made during respiration. ATP is made from ADP, adenosine diphosphate, by the addition of an inorganic phosphate via a condensation reaction and using the enzyme ATP synthase. ATP can be broken down, or hydrolyzed, into ADP + Pi by a hydrolysis reaction and the enzyme ATP hydrolase.
ATP + H2O -> ADP + Pi
The bonds between the inorganic phosphate groups are high energy bonds, as shown in the diagram above. Therefore, by breaking one of these bonds, a small amount of energy is released to the surroundings, which can be used in chemical reactions. This is why ATP is an immediate energy source- only one bond has to be hydrolyzed to release energy, and as ATP cannot be stored, this occurs straight away. It is essential to remember that ATP cannot be stored.
ATP is not only able to release energy to the surroundings, but it can also transfer energy to different compounds. The inorganic phosphate released during the hydrolysis of ATP can be bonded onto completely different compounds to make them more reactive. This is known as phosphorylation, and this actually happens to glucose at the start of respiration to make it more reactive.
ATP Properties
There are five key properties that ATP has, making it a suitable immediate source of energy. In exam questions, ATP properties are frequently compared to glucose to emphasize why ATP is the immediate source of energy for cells rather than glucose. This is explained and demonstrated in the five points below.
1. ATP releases energy in small, manageable amounts so no energy is wasted.
This means that cells do not overheat from wasted heat energy, and cells are less likely to run out of resources. In comparison to glucose, which would release large amounts of energy that could result in wasted energy.
2. It is small and soluble so easily transported around the cell.
ATP can move around the cytoplasm with ease to provide energy for chemical reactions within the cell. This is a property ATP has in common with glucose.
3. Only one bond is broken/hydrolyzed to release energy, which is why energy release is immediate.
Glucose would need several bonds to be broken down to release all its energy.
4. It can transfer energy to another molecule by transferring one of its phosphate groups.
ATP can enable phosphorylation, making other compounds more reactive. Glucose cannot do this, as it does not contain phosphate groups.
5. ATP can’t pass out of the cell, the cell always has an immediate supply of energy.
ATP cannot leave the cell, whereas glucose can. This means that all cells have a constant supply of ATP or ADP + Pi, but a cell can run out of glucose.
- What is the function of ATP?
- Your answer should include: Immediate / Source / Energy
RNA
RNA is a polymer of a nucleotide formed of a ribose, a nitrogenous base, and a phosphate group. The nitrogenous bases in RNA are adenine, guanine, cytosine, and uracil. RNA has the base uracil instead of thymine. In comparison to the DNA polymer, the RNA polymer is a relatively short polynucleotide chain and it is single stranded.
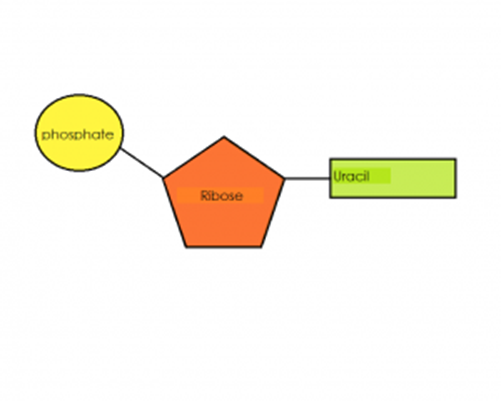
The function of RNA is to copy and transfer the genetic code from DNA in the nucleus to the ribosomes. Some RNA is also combined with proteins to create ribosomes.
Three Types of RNA
There are three types of RNA: mRNA, tRNA, and rRNA.
mRNA
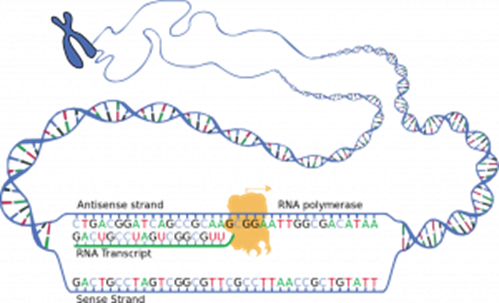
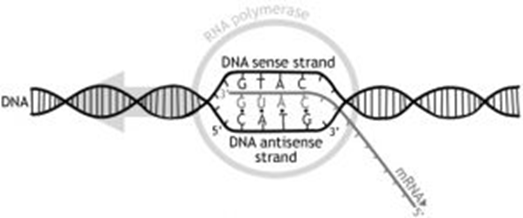
Messenger RNA is a copy of a gene from DNA. The diagram below shows how mRNA is created from a DNA template. mRNA is created in the nucleus and then leaves the nucleus to carry the copy of the genetic code of one gene to a ribosome in the cytoplasm. DNA is too large to leave the nucleus and would be at risk of being damaged by enzymes, therefore destroying the genetic code permanently. mRNA is much shorter because it is only the length of one gene and can therefore leave the nucleus. mRNA is short-lived as it is only needed temporarily to help create a protein. Therefore, by the time any enzymes could break it down, it would have already carried out its function. mRNA is single stranded, and every 3 bases in the sequence code for a specific amino acid. These three bases are therefore called codons.
Polynucleotides
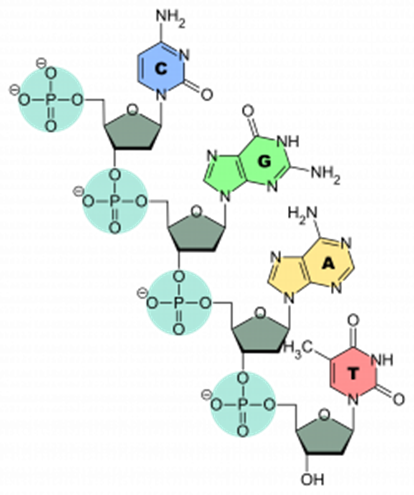
The polymer of these nucleotides is called a polynucleotide. It is created via condensation reactions between the deoxyribose sugar and the phosphate group, creating a phosphodiester bond. Phosphodiester bonds are strong covalent bonds and therefore help ensure that the genetic code is not broken down.
The polynucleotide has a sugar-phosphate ‘backbone’. This is describing the strong covalent bonds between the sugar and phosphate groups that hold the polymer together.
The DNA polymer occurs in pairs, and these pairs are joined together by hydrogen bonds between the bases. This is how the double helix structure is created, as two chains twist.
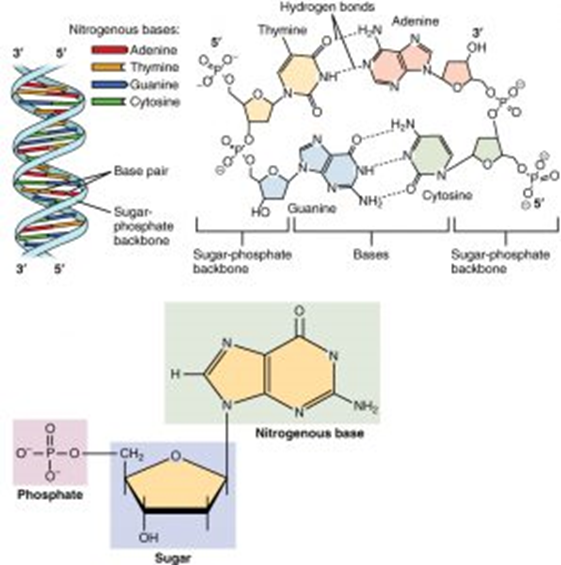
Hydrogen bonds can only form between complementary base pairs. This is the term given to the fact that the base cytosine can only form hydrogen bonds with guanine and that adenine can only bond with thymine. Adenine and thymine form 2 hydrogen bonds, whereas cytosine and guanine can form 3 hydrogen bonds. This complementary base pairing is important to help maintain the order of the genetic code when DNA replicates.
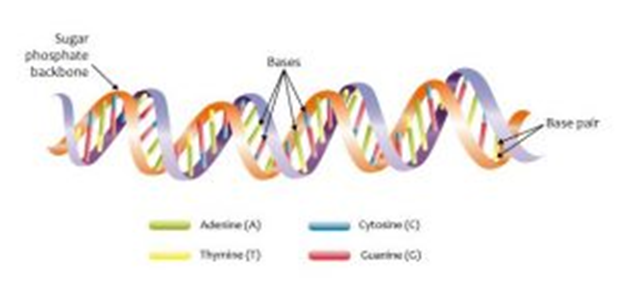
How DNA Structure Relates to its Function
- Stable structure due to sugar-phosphate backbone (covalent bonds) and the double helix
- Double stranded so replication can occur using one strand as a template
- Weak hydrogen bonds for easy unzipping of the two strands in a double helix during replication.
- Large molecule that carries LOTS of information
- Complementary base pairing allows identical copies to be made.
- What are the monomer units called in DNA?
- Nucleotide
- Name the 3 parts of this monomer unit?
- Your answer should include: Phosphate / Deoxyribose / Nitrogenous / Base
- If the base sequence on 1 strand of DNA is GTTACCGTA what would the sequence be on the other strand?
- CAATGGCAT
- If 19.9% of the base pairs in DNA are Guanine, what percentage is Thymine?
- Your answer should include: 30.1% / 30.1
Three Types of RNA
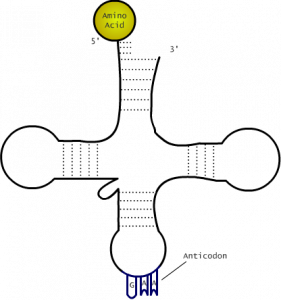
Transfer RNA is found only in the cytoplasm. It is single stranded but folded to create a shape that looks like a cloverleaf. This cloverleaf shape is held in place by hydrogen bonds, demonstrated with the dashed lines in the diagram below. The function of tRNA is to attach to one of the 20 amino acids and transfer this amino acid to the ribosome to create the polypeptide chain. Specific amino acids attach to specific tRNA molecules, and this is determined by 3 bases found on the tRNA which are complementary to the 3 bases on mRNA. These are called the anticodon because they are complementary to the codon on mRNA.
DNA
Deoxyribonucleic Acid (DNA) codes for the sequence of amino acids in the primary structure of a protein, which in turn determines the final 3D structure and function of a protein. It is essential, therefore, that cells contain a copy of this genetic code and that it can be passed on to new cells without being damaged.

The DNA polymer is a double helix, and in this lesson, details about the monomers will be covered as well.
The monomer that makes up DNA is called a nucleotide. It is made up of deoxyribose (a pentose sugar), a nitrogenous base, and one phosphate group.
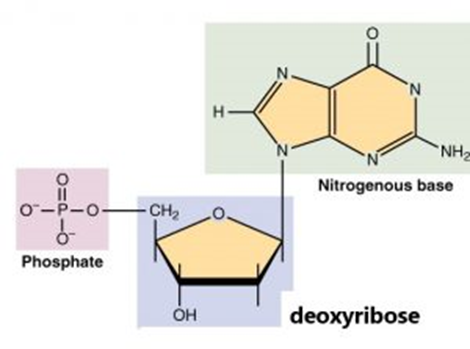
The nitrogenous base can be guanine, cytosine, adenine, or thymine.
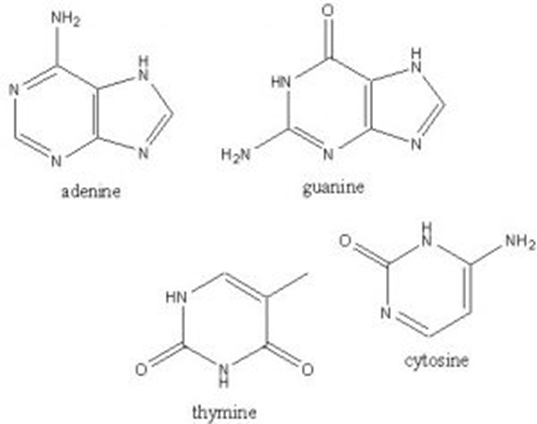
These bases are classified as either purines or pyrimidines, depending on whether the base is a single or double-ring structure.
Adenine and guanine are both double-ring and are therefore purines.
Thymine and cytosine are both single-ring structures and are therefore pyrimidines.
DNA Replication
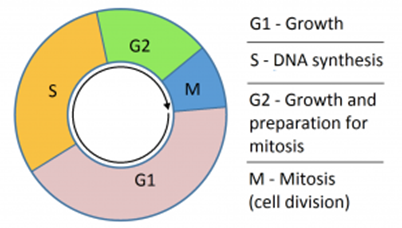
In order for new cells to be created, all the DNA in a cell must be replicated first to ensure that when the cell splits in half, each new cell still contains the full amount of DNA. This occurs in the S-phase of interphase in the cell cycle.
When describing the DNA double helix, the top and bottom of each strand are described as either the 3’ (prime) end or the 5’ (prime) end. This number refers to which carbon within the deoxyribose sugar of the nucleotide is closest to the top/bottom – see the diagram below. This is relevant because an enzyme that catalyzes DNA replication is complementary in shape to the 3’ end, and can therefore only attach to the DNA at this location.
Stages of DNA Replication
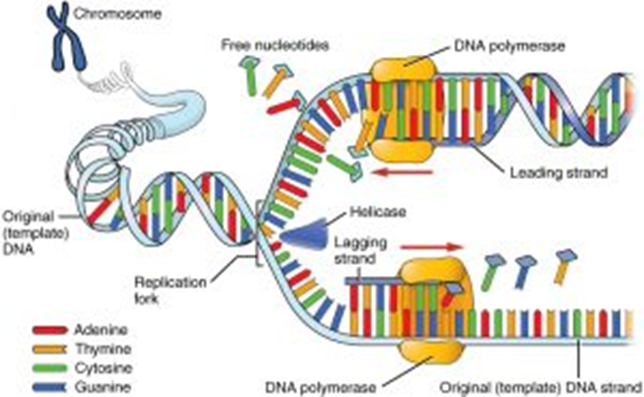
Before the DNA can be copied, the double helix must first unwind. The enzyme DNA helicase breaks the hydrogen bonds between the complementary bases of the two DNA polymers within the double helix. This causes the double helix to unwind, and the two strands to separate or unzip. These two separated strands both act as templates for DNA replication. The point at which the unzipping stops is called the replication fork. Not all the DNA is unzipped in one go, as this increases the chances of copying errors resulting in mutations.
Within the nucleus, there are free-floating DNA nucleotides. If a free-floating DNA nucleotide aligns next to a complementary base on either template strand of DNA, then hydrogen bonds will form between them. The enzyme DNA polymerase is responsible for then forming the phosphodiester bond between these nucleotides to create a new polymer chain of DNA.
DNA polymerase can only attach at the 3’ end and, therefore, will move along the template strand in the 3’ to 5’ direction. When the enzyme is moving towards the replication fork, the new strand is referred to as the ‘leading strand’ and can be created in one continuous go. On the antiparallel strand, the DNA polymerase still attaches at the 3’ end and works down towards the 5’ end, but this is directly next to the replication fork. Therefore, every time the replication fork unwinds further, the enzyme has to reattach to the 3’ end, and this creates small fragments of DNA. This strand is called the ‘lagging strand’ and the small fragments are called Okazaki fragments. The Okazaki fragments are later joined together by the enzyme DNA ligase.
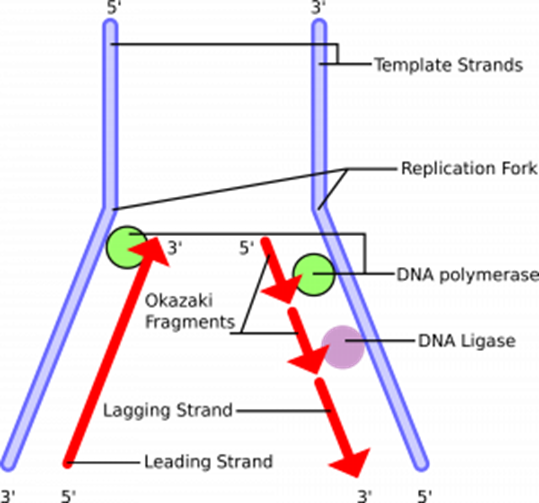
Both DNA template strands are now replicated, and this process continues until the entire length of DNA is replicated.
Semi-Conservative Replication
DNA replication is described as semi-conservative because, in replication, one strand is conserved, and one new strand is created.
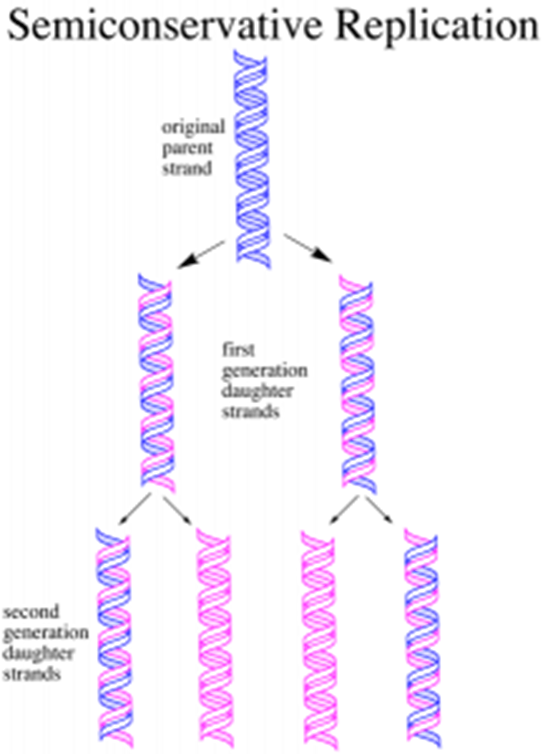
Meselson and Stahl performed the experiment below to prove this.
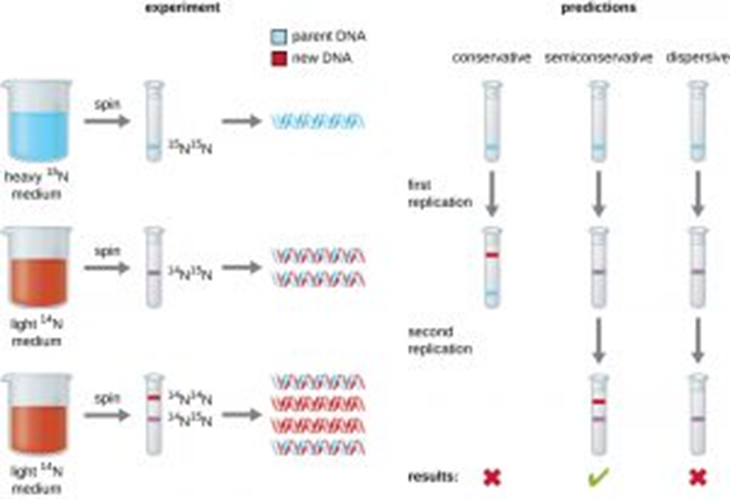
Bacteria were grown in a solution containing the 15N isotope. This is a heavier form of nitrogen. During replication, all the new DNA molecules incorporated will contain this isotope in the nitrogenous base. The DNA is therefore heavier, and this is demonstrated by centrifuging and seeing the DNA band settling at a lower point in the test tube.
A sample of this bacteria is then transferred to a solution containing only the 14N lighter isotope of nitrogen and left to replicate once only. All the DNA newly synthesized will now be lighter. After centrifugation, all the DNA settles in the middle of the test tube, which shows that in DNA replication, 50% of the old DNA is always conserved, and 50% of the DNA is new.
The bacteria are left to replicate for a second time in the light 14N medium. After another round of semi-conservative replication, the results can be seen above. There will now be two double helices composed of completely light DNA and two double helices that contain one heavy strand and one light strand.
The Genetic Code
The genetic code has three special features: it is degenerate, universal, and non-overlapping. At the start of every gene, there is a ‘start codon’ TAC in DNA or AUG in mRNA. This codes for the amino acid methionine. This methionine is later removed from the protein if it is not actually needed for the structure. At the end of every gene, there are 3 bases that do not code for an amino acid and are known as a ‘stop codon.’ These stop codons mark the end of a polypeptide chain and stop translation from occurring further. These codons are ATT, ATC, and ACT on DNA.
Degenerate
There are 20 amino acids that the genetic code has to be able to code for. There are four DNA bases (GCTA), and therefore, three bases are needed to make enough combinations to code for at least 20 amino acids.
This can be proven mathematically:
- If one base coded for one amino acid, this would only allow for 4 amino acids to be coded for. This is insufficient to code for 20 amino acids.
- If two bases coded for one amino acid, this would allow for 16 amino acids to be coded for (4x4 combinations of code). This is insufficient to code for 20 amino acids.
- If three bases coded for one amino acid, this would allow for 64 amino acids to be coded for (4 x 4 x 4 combinations of code).
64 combinations are more than is needed to code for 20 amino acids, and as a result, each amino acid is actually coded for by more than one triplet of bases. This is what is meant by the genetic code being degenerate. For example, tyrosine is coded for by ATA and ATG.
This genetic code wheel enables you to work out all combinations of bases that code for each of the 20 amino acids (the amino acids are on the outside of the wheel abbreviated to the first three letters of each one).
Universal
The same triplet of bases codes for the same amino acid in all organisms; this is why the genetic code is described as being universal.
Non-Overlapping
Each base in a gene is only part of one triplet of bases that codes for one amino acid. Therefore, each codon, or triplet of bases, is read as a discrete unit.
Introns and Exons
Introns are sections of DNA that do not code for amino acids and, therefore, polypeptide chains. These get removed, spliced, out of mRNA molecules.
Exons are the sections of DNA that do code for amino acids.
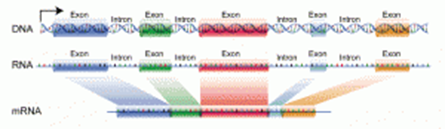
- If all the DNA were distributed equally between the chromosomes, calculate the mean length of DNA in each one. (in meters)
- Your answer should include: 0.05m / 0.05
Protein Synthesis
Proteins are created on the ribosomes.
The production of proteins from the DNA code within DNA occurs in two main stages:
-
Transcription – where the DNA code for one gene is copied into mRNA.
-
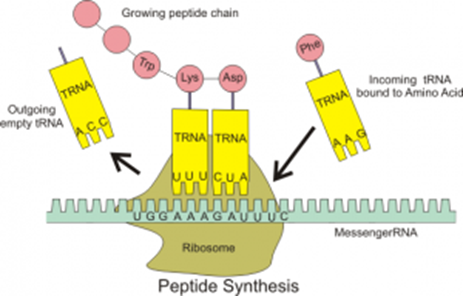
Translation – where the mRNA joins with a ribosome, and a corresponding tRNA molecule brings the specific amino acid the codon codes for.
mRNA is a short, single-stranded molecule found in both the cytoplasm and nucleus. It is produced during transcription in the nucleus and is complementary to the DNA sequence. In mRNA, groups of three adjacent bases are called codons.
tRNA molecules are found in the cytoplasm and have amino acids attached to them. Each tRNA is specific to one amino acid, determined by the anticodon on it (a three-base sequence). Each tRNA molecule has an anticodon that is complementary to the codons on mRNA. tRNA is involved in translation, carrying the amino acids used to make proteins to the ribosomes. tRNA is a single polynucleotide strand folded into a clover shape, held together by hydrogen bonds between base pairs.
Transcription
This is the process in which a complementary mRNA copy of a gene in the DNA is created in the nucleus. mRNA is much smaller than DNA, allowing it to carry the genetic code to the ribosome in the cytoplasm to facilitate protein synthesis.
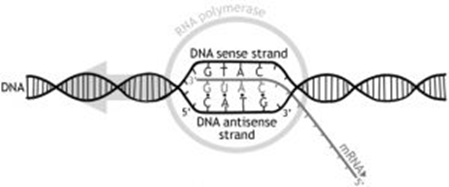
The DNA helix unwinds to expose the bases, serving as a template. Only one strand of the DNA acts as a template, known as the antisense strand. Similar to DNA replication, this unwinding and unzipping are catalyzed by DNA helicase, breaking the hydrogen bonds between bases. Free mRNA nucleotides align opposite exposed complementary DNA bases. The enzyme RNA polymerase bonds the RNA nucleotides together to create a new RNA polymer chain, copying an entire gene. Once copied, the mRNA is modified and then exits the nucleus through nuclear envelope pores.
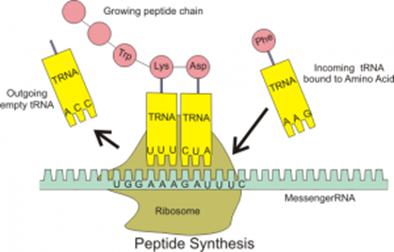
Translation
This is the stage in which the polypeptide chain is created using both the mRNA base sequence and tRNA.
Once the modified mRNA has left the nucleus, it attaches to a ribosome in the cytoplasm. The ribosome attaches at the 3' end of the mRNA at the start codon, AUG. The tRNA molecule with the complementary anticodon to the AUG codon aligns opposite the mRNA, held in place by the ribosome. The ribosome moves along the mRNA molecule to enable another complementary tRNA to attach to the next codon on the mRNA. The two amino acids delivered by the tRNA molecule are then joined via a peptide bond, catalyzed by an enzyme. This process continues until the ribosome reaches the stop codon at the end of the mRNA molecule. The stop codon does not code for an amino acid, so the ribosome detaches, and translation ends. The polypeptide chain is now created and will enter the Golgi body for folding and modification.
- Transcribe the following DNA code: TACGGCTTACGACCACGACCCAAATAGATT (Without spaces in your answer)
- AUGCCGAAUGCUGGUGCUGGGUUUAUCUAA
- Where does transcription take place?
- Nucleus
- What is made during transcription?
- mRNA
- What happens after transcription?
- Translation
